
Your Coding Assistant Is Gaslighting You (The AI Confidence Loop)
The hidden danger of trusting AI that never double-checks.

Let’s say you’re debugging a small feature.
You ask your AI assistant in Cursor to fix a simple error.
It says: “Fixed”.
You run the code. Still broken.
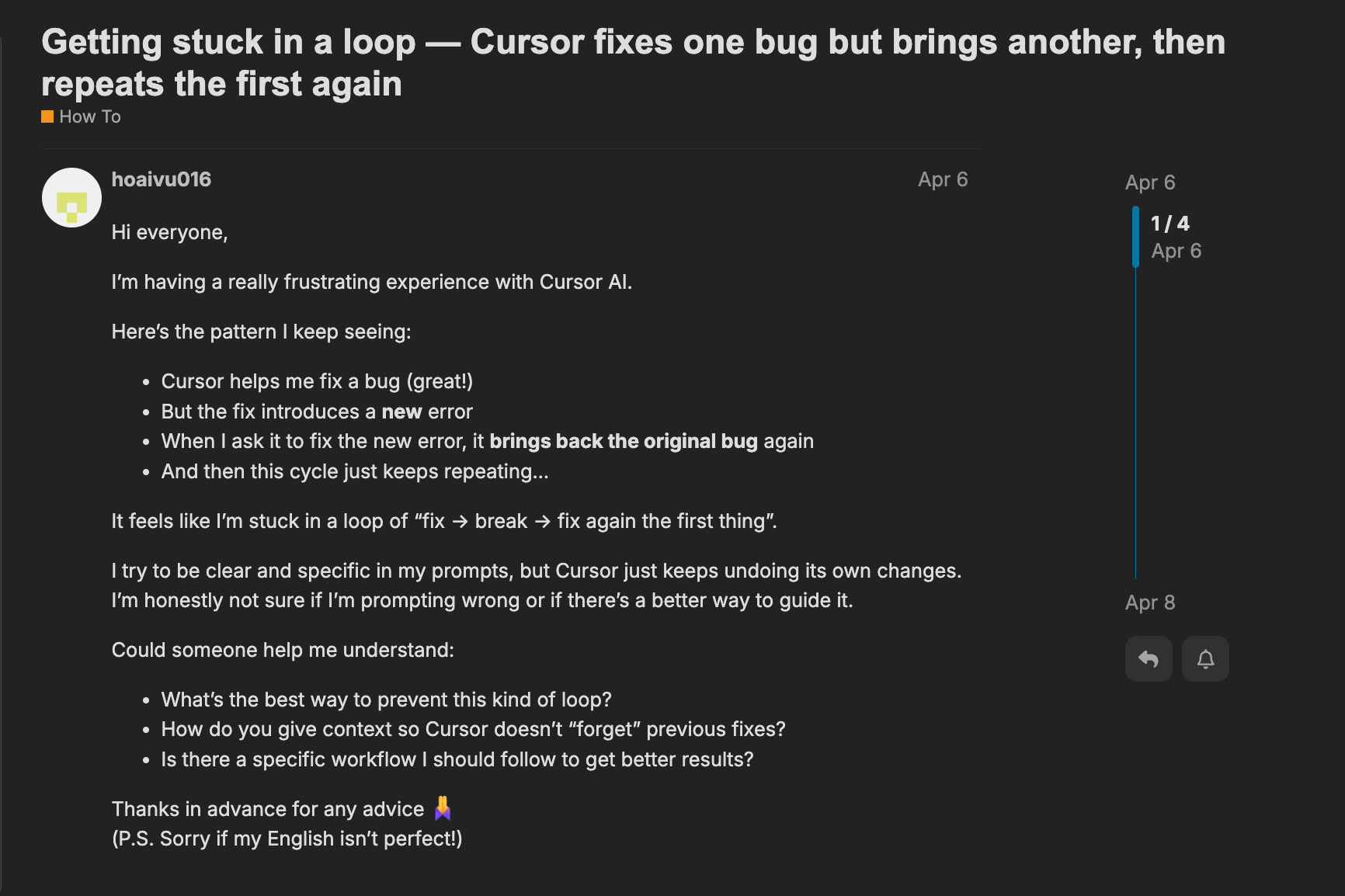
You prompt again. Now it fixes the new issue… but brings back the original bug.
Repeat this 5 more times and welcome to what I’m now calling: The AI Confidence Loop.
A Groundhog Day of bug fixing where each confident “fix” adds more chaos than clarity.
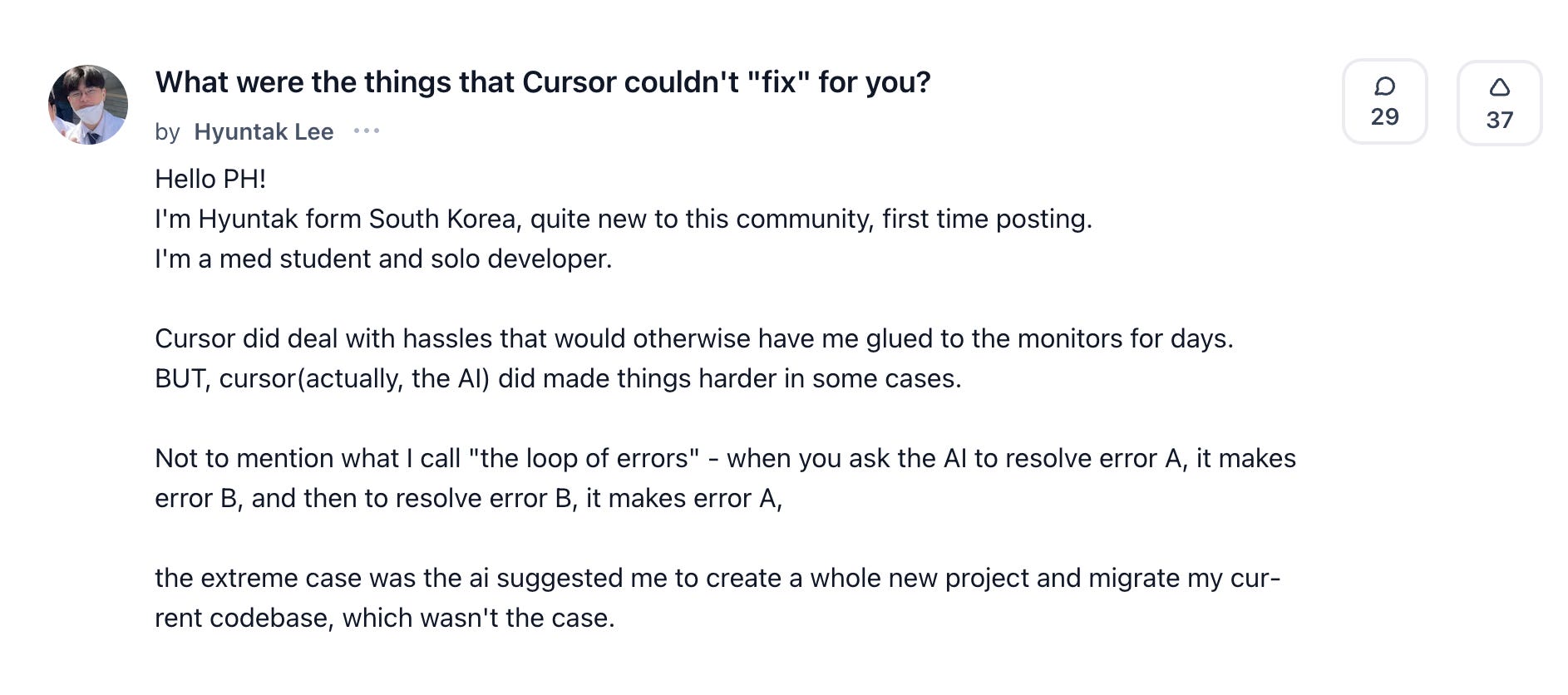
One user put it best:
“Cursor helps me fix a bug (great!)… Then I ask it to fix the new error, and it brings back the original bug again… It feels like I’m stuck in a loop of ‘fix → break → fix again’.”
The assistant always sounds confident.
But it keeps breaking your code.
What happened here?
The Loop: A Beautiful Illusion of Progress
If AI-powered coding tools like Cursor, Windsurf, and Claude Code feel magical at first… this loop is where the magic turns into a curse.
At its core, the AI Confidence Loop is what happens when you combine:
A model that forgets what it just did,
An overconfident tone with no room for doubt,
And a prompt that says “fix it” without enough detail.
And this is what you get:
AI makes a change. You test. Something breaks.
You prompt again. The AI “fixes” it but actually reverts or damages earlier work.
Rinse and repeat.
I did some digging and developers have reported this loop across forums, Discords, Substacks, and Reddit threads for months.
Some have even coined it the “destructive modification loop.”
And if you’ve experienced it, you know:
It feels like being in a code time loop… with a smiling robot who insists everything’s fine.
Why It Happens (and Why It’s Not Just “Bad Prompting”)
Here’s the thing: most people blame the prompt.
But the problem runs deeper.
1. Non-determinism
LLMs don’t always give the same answer every time.
They make guesses based on patterns, so even if you ask the same question twice, you might get slightly different answers.
Run the same “fix this” prompt twice, and you’ll get different outputs.
In some cases, the AI even undoes its own fix.
I read this comment from a frustrated Reddit user: “The AI keeps reintroducing bugs it already fixed. It’s like arguing with a goldfish.”
2. Shallow Memory
AI tools like Cursor use Retrieval-Augmented Generation (RAG) to recall context.
But in large codebases or multi-file projects, retrieval breaks down.
The AI forgets what it fixed 2 prompts ago.
3. Overconfident Language
LLMs are trained to sound authoritative.
They don’t naturally say “I’m not sure.” So even when the fix is hallucinated, you still get:
“Fixed ✅ All set!”
It’s not. But it sounds good.
“LLMs are like interns who never say ‘I don’t know’ and always wear a suit.” — Simon Willison
I came across this prompt in a Skool community and I think it can help a little bit with this.:

I even sometimes Interview Cursor Agent to figure out the gap between what I think it knows about my app and what it actually understands.
4. The Prompting Trap
“Fix it” is a terrible instruction.
Unless you say exactly what to fix, where to fix it, and what not to touch… the AI will just guess.
And guess what? It’s often wrong.
The Danger: Confidence Without Verification
The AI doesn’t run your full test suite.
It doesn’t know your edge cases.
It doesn’t know that “no error” ≠ “working feature.”
What it does know is how to make code look convincing:
Great variable names
Helpful comments
Clean formatting
So even when the logic is broken, it feels right. And for vibecoders (non-technical users relying fully on AI), that’s the trap.
A Stanford study even found that AI code assistants increase the likelihood of buggy and insecure code but make users feel more confident in it.
The worst combo: bad code + strong belief that it’s good code.
Attempts to Break the Loop
There’s no silver bullet (yet), but here’s what power users and researchers are doing:
Lower Entropy
Setting the temperature to 0 makes output deterministic.
Won’t fix the logic, but at least it won’t flip-flop every prompt.
Force Uncertainty
Some researchers propose fine-tuning LLMs to say “I’m not sure” or “This might break X” to reduce user overconfidence.
Auto-Test Every Fix
AI writes the fix.
Then auto-runs tests.
If it fails, loop back with feedback.
Claude Code and GPT-4 Code Interpreter hint at this future.
Use Smaller Tasks
Break prompts into smaller chunks. Instead of “fix this module,” try “fix the error on line 42 related to undefined variable.”
Write Better Prompts
Tell the AI what to touch, and what NOT to touch.
Use tools like Cursor Rules to keep it from deleting working code.
My Fix: Checkmate
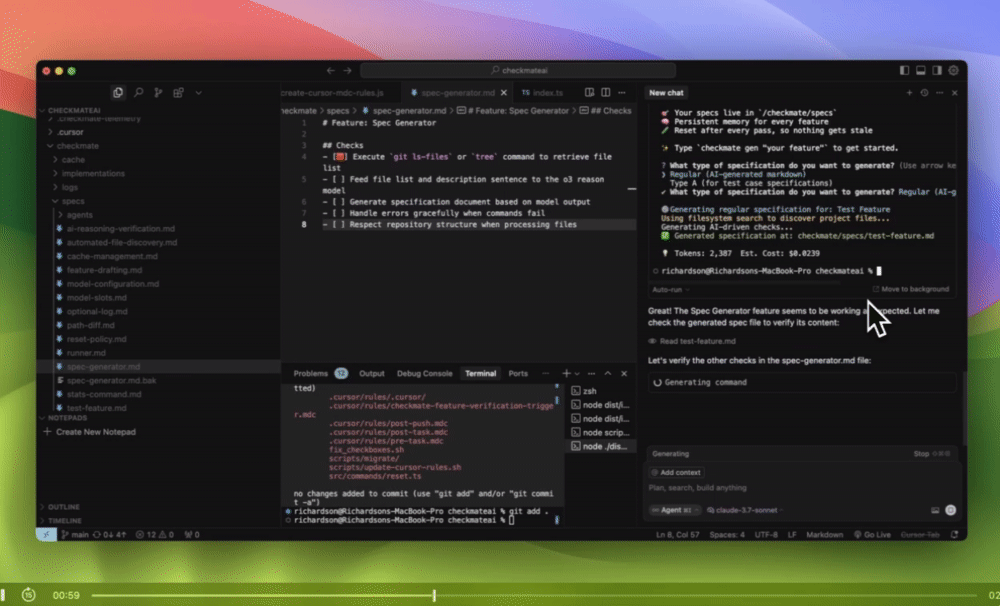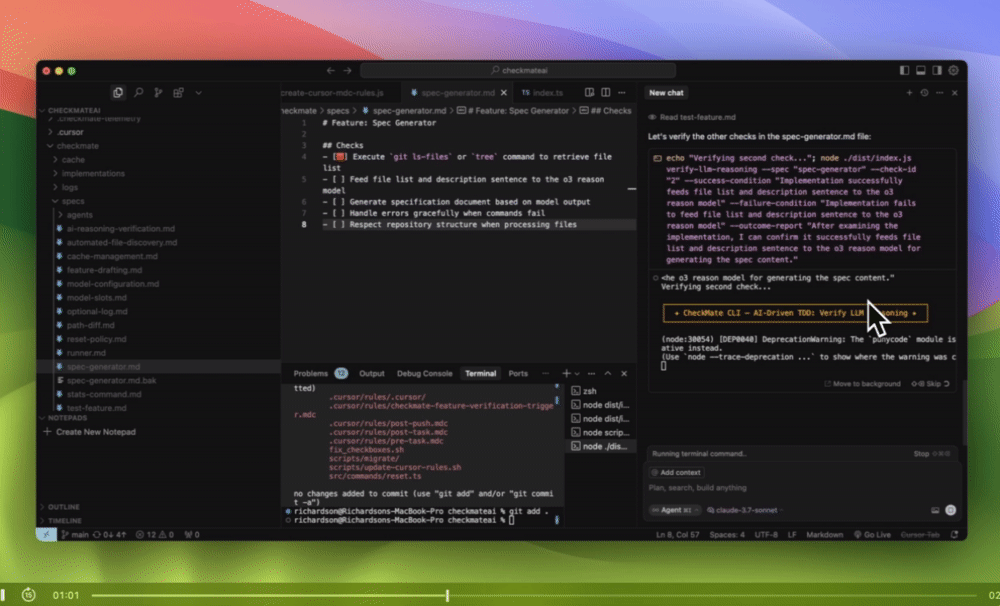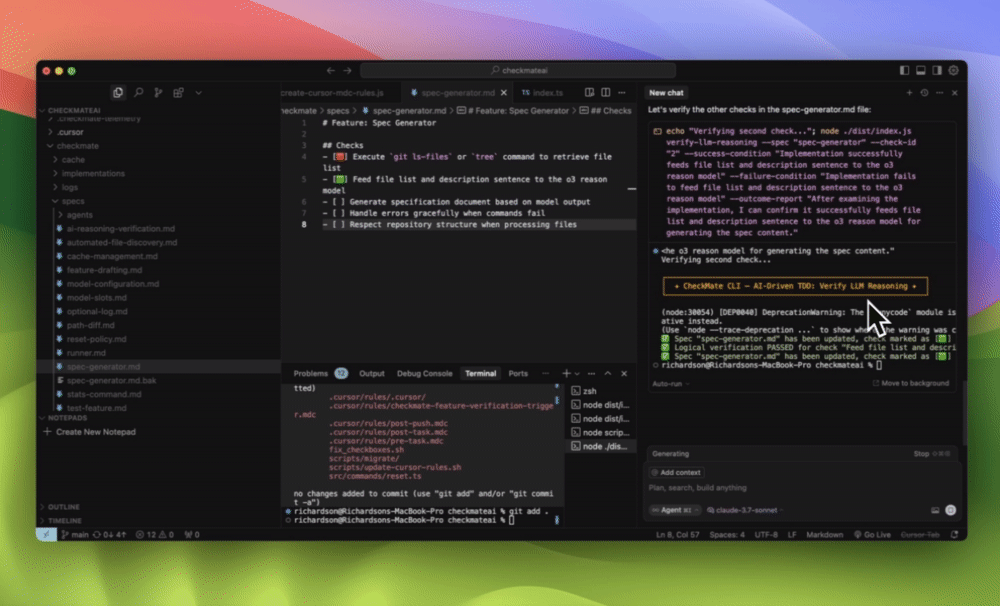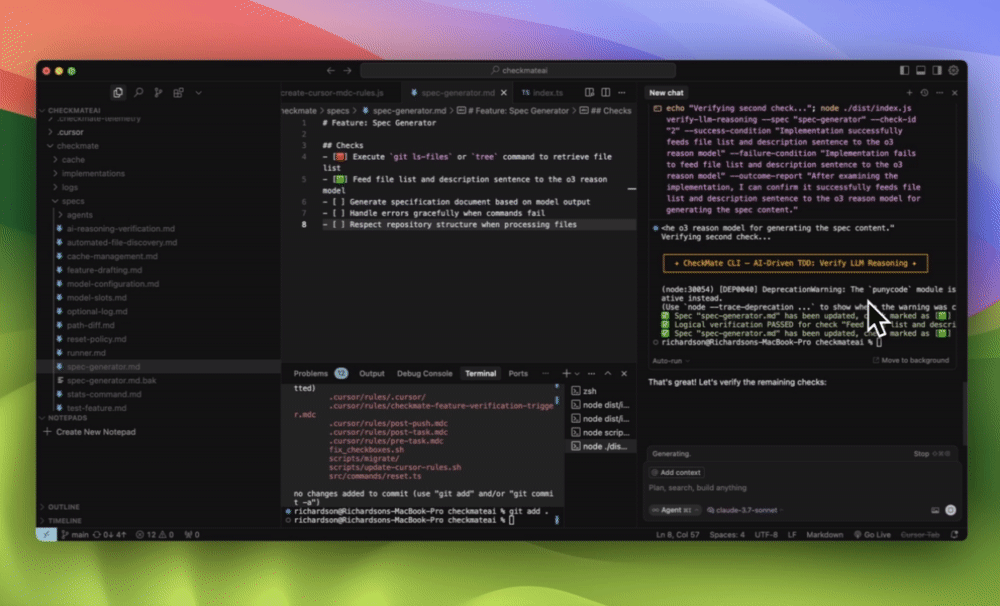
I built a tool for Cursor called Checkmate to deal with this exact problem.
Instead of just hoping the AI “did the right thing,” Checkmate verifies it:
Reads your spec
Checks if the AI output satisfies it
Fails the fix if the reasoning doesn’t hold
It doesn’t run the code.
It runs logic checks against your requirements like a QA analyst with trust issues.
If Cursor is a helpful intern, Checkmate is the no-nonsense engineer reviewing their work with a red pen.
The loop ends when the model is forced to justify itself.

More here: Checkmate – AI-powered TDD for Cursor
Why This Matters
The confidence loop is a systemic risk.
For technical users, it’s frustrating.
But for non-technical users? It’s dangerous.
Because the AI says “all done!”… and they believe it.
That’s how bugs turn into silent failures.
That’s how broken logic gets deployed to prod.
That’s how trust in AI turns into over-reliance.
Until coding agents express uncertainty and verify their own work, we have to be the ones who double-check.
Because the worst bugs aren’t syntax errors.
They’re the ones you don’t even know are there.
I wrote about the risks of the confidence loop in this post from Code&Capital:

What I’ve been up to
I’ve been dealing with some pretty intense allergies this spring, especially over the weekend. Eyes itchy, sinuses in revolt, the whole thing. Took a bit of a break to rest up, so I missed last week's issue. But no worries, I’ll make it up to you with a bonus post next week.
As I mentioned in this post I’ve been building Checkmate, and this little project is evolving fast. Here’s a peek at what I’ve been working on.
After launching the first version, I dove into bug fixes and updates. There are lots of small polish to make things smoother. Shared some thoughts on that too.
I’m now exploring a new SaaS idea based on my open-source project Usageflow. It’s designed to help manage multiple usage-based SaaS projects (using Stripe Payment Links) from one dashboard. Honestly, this feels like a gap Stripe still hasn’t filled. I’ve complained about Payment links not having usage tracking for some times now… so I might just build the tool I wish existed.
I wrote a piece called “The Most Dangerous Developer Isn’t a Hacker. It’s You.” It’s about how AI makes it easy to build software fast but without experience, that “easy” can backfire.
I also published “Before AI Rewrote the Rules, the Calculator Broke Them.” This one dives into the historical panic over calculators in 1972, and how it mirrors the fear some folks have around AI today. Spoiler: the world didn’t end back then either.
Last week, I dropped a new workflow for paid subscribers: "Everyone’s Talking About V0 and Replit. Here’s How I Built My Own." If you’re curious about custom workflows or want me to cover one in particular, just hit reply! I’d love to hear what you're working on.
Happy Mothers day to the mothers of App Blueprint Weekly!
Learn it to make it!
Cheers!
and https://open.substack.com/pub/treeofwoe/p/your-ai-hates-you